介绍
该论文解决的问题:
- 没有源数据集,只有在源数据集上训练的模型,怎样进行迁移学习
- 如何判断某个
target data为哪个class target data没有ground truth时,如何解决训练时发生分类偏移的情况
针对上面三个问题,论文提出了对应的解决方法
- 设计新的网络结构
- 设计
APM模块对target data进行分类 - 设计
Confidence-based filtering来制约
下面介绍根据这三个解决方法进行介绍
论文主要内容
设计新的网络结构
结构
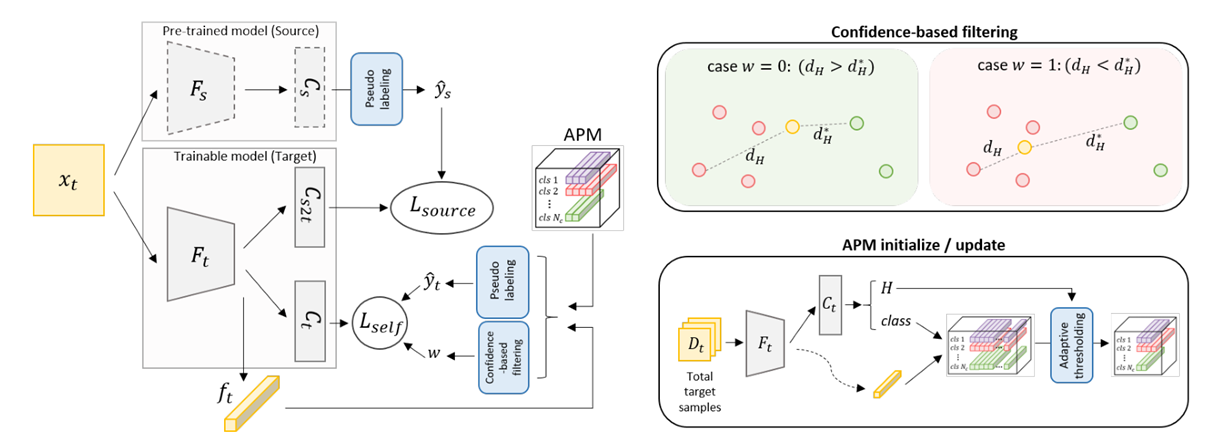
这个网络主要有三部分:pre-trained model,trainable model和APMpre-trained model:在source data上预训练好的模型,在整个训练过程中不变trainable model:论文中要在target data上训练的模型,初始化时:APM:存放每个类别的代表样本,当有样本送到网络中时,与里面的代表样本计算距离,然后打分,打分高的类别就贴上对应的label
训练过程
- 初始化
trainable model,参数Fs->Ft,Cs->Cs2t,Cs->Ct target data送到pre-trained model中得到伪标签ys,根据ys计算Lsource,计算公式如下:
target data送到trainable model中,得到特征ft,ft送到APM中得到类别,和对应的伪标签yt,公式如下:其中Pc为每个样板- 计算
ft打分最高的两个类别,然后计算ft与两个类别的霍思达夫距离,判断是否舍弃不合理的样本。公式如下 - 根据
ys和w计算Lself和总的Loss,计算公式如下:
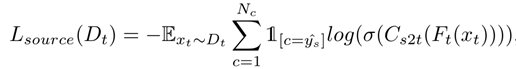
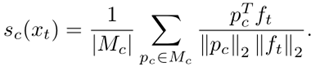
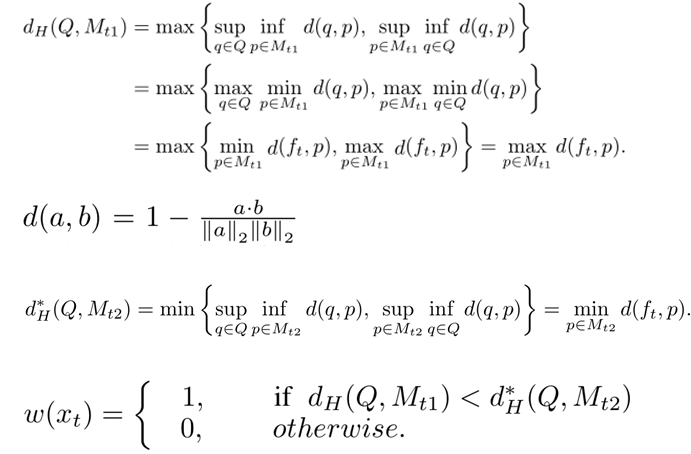
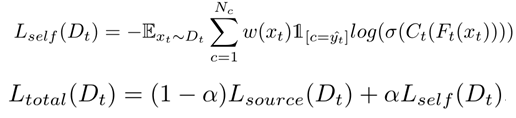
设计APM模块
APM中存放每个类的代表性样本(样板),作者提出自熵越小的样本越有资格作为样板。每个类别有多少个样板?作者提出了自适应的阈值。APM初始化和更新方式:
- 计算样本的熵,
l(xt)为Ct得到的类别概率 - 对于每个类别得到一个熵集
- 取所有熵集中最小值的最大值作为阈值
- 如果一个样本的熵 < 阈值,那么将这个样本作为样板
上述公式如下: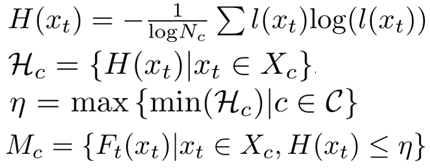
设计Confidence-based filtering
这个主要解决一个问题:target data没有正确的ground truth,训练的过程容易发生偏移。具体可见训练过程中的第四步。
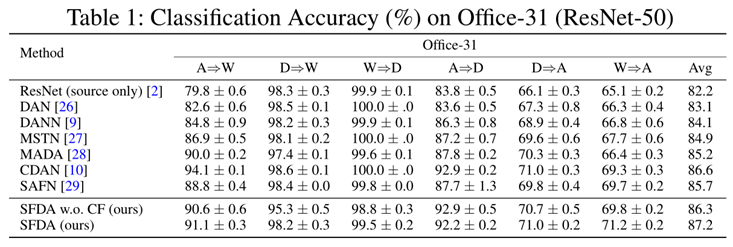
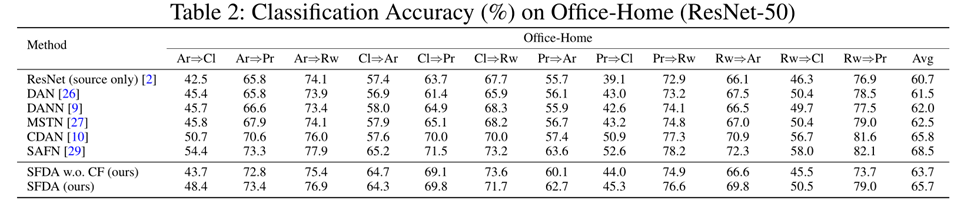
实验结果
实验结果如下: